
Your AI Research Is Probably Right. That's the Problem.
AI Hallucinations Aren't the Issue. Your Workflow Is.


The research looked right. The citations were formatted correctly. The claims tracked with what I knew about the subject. I’d been working in Perplexity for a couple of projects and had used it to create solid-looking documentation. I had already sent the first document the previous day and was about to send the second.
Then I stopped.
Not because I found an error, but because I realized that I had not checked the first document exhaustively for hallucinations and incorrect citations.
Both these documents were important, and they could not have incorrect information. I thought, do I read every citation by hand? That sounded very painful and very 20th century. Instead, I built tools. I applied those tools to the document I was about to send, and ran them retrospectively on the one I’d already sent. The one I was about to send passed and I sent it. The old document passed, too. I felt relieved.
The relief told me everything. If I were confident in my process, I wouldn’t feel relieved. I’d feel confirmed. Relief is what you feel when you got lucky.
I don’t want to get lucky. So I’ve changed how I work.
THE CITATION PROBLEM DIDN’T START WITH AI
A substantial and growing share of citations in peer-reviewed medical literature are fake, misattributed, or impossible to verify against their stated sources. This isn’t a new revelation — it’s been documented in bibliometric research for years — but AI has considerably accelerated the scale of the problem. We’re trained to read confidence as accuracy. That makes a model that sounds authoritative and wrong more dangerous than one that sounds uncertain and wrong.
In my previous piece on Bixonimania, I discussed how easy it is to be duped by “authoritative and wrong” sources. I thought about the point I made in that piece about using AI to govern AI, so I built a hallucination auditing tool in Gemini to check any documents I fed into the Gem. I did a test run on a document and it turned up 20 claims and zero hallucinations. That sounded reassuring. A separate audit of a different document found 17 citations checked and found 5 that had correct citations but the conclusions didn’t actually match the content in the document. This included a 23-percentage-point improvement figure that was actually closer to 14 percentage points. Incorporating this would have inflated downstream financial projections by roughly 64%. The document looked credible. The citations were real and had content that was close to what the document contained. The errors were in the specifics, exactly where they’re hardest to catch in a quick read.
The point isn’t that AI-generated content is unreliable. The point is that the reliability isn’t evenly distributed across a document. Most claims check out completely. Others don’t exist in the cited sources at all. The problem is that you can’t tell which is which, even when the document reads fluently.
WE ARE USING THESE TOOLS WRONG
The dominant mode of AI use I see — in healthcare and especially with general use — is what I’ve started calling super-Google. Someone has a question. They put it into the model. They read the output. They use it.
That is a perfectly fine way to use a search engine. It is a profound waste of what these tools can actually do.
Search engines retrieve. That is their job. LLMs reason, synthesize, evaluate, compare, and generate. They can serve as research assistants, editors, critics, validators, and auditors. They can hold multi-step methodologies and apply them consistently at scale. Most importantly for this use case, they can check their own work and each other’s work. The tool that helped you produce a document can also interrogate that document. A different tool, with a different architecture and different training, can run the same interrogation and flag where its conclusions diverge.
None of that is accessible in the super-Google mode. Super-Google is one shot with no context. You ask, it answers, you stop. The model’s capability is limited to the keystrokes in the question.
The people I see getting the most out of these systems are using them iteratively, layering tools, building workflows that chain outputs into inputs for the next step. Instead of asking simple questions, they’re building pipelines.
USING AI TO GOVERN AI
What I built was simple in concept but a bit more complex in execution. A Gemini Gem configured as a hallucination auditor, with instructions to check factual claims against sources and return a structured scorecard: listing claim by claim, existence verified or not, semantic accuracy assessed, reasoning documented. To create even more redundancy, I created a parallel Claude skill with the same function. I used NotebookLM’s researching and synthesis capabilities to help me create both.
The Gemini Gem is faster. When I asked NotebookLM why, the explanation involved Thought Signatures. These are Gemini’s ability to preserve chain-of-thought state through web search interruptions, so the model can pause, retrieve external sources, and resume its reasoning without reconstructing context from scratch. Whether that explanation is fully accurate or is itself an artifact of how NotebookLM describes its own architecture, the performance difference is real and reproducible in my use.
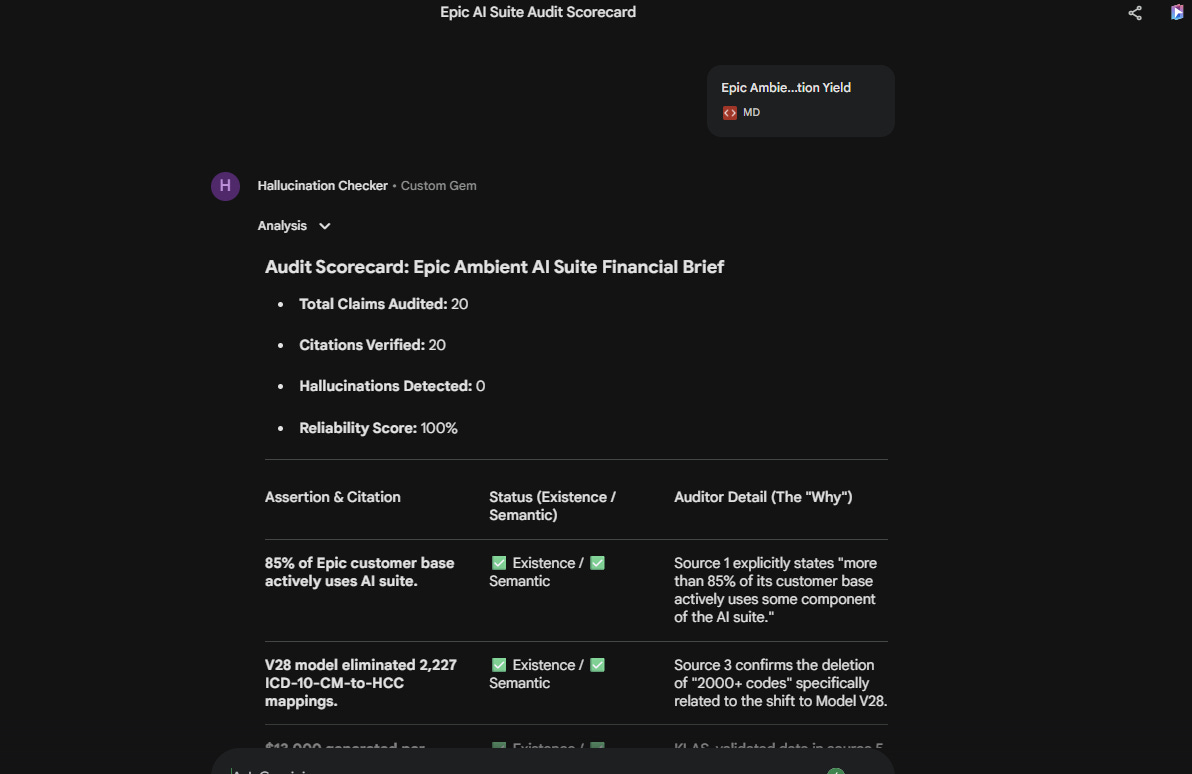
The Claude skill produced better initial output. The structured reasoning was more granular, the auditor detail richer, the failure modes more precisely described. I then used the Claude skill prompt to refine the Gemini Gem prompt. The tools are not interchangeable, and treating them as interchangeable would miss the point.

Here is the important part: they sometimes disagree.
When two tools audit the same document and return discordant findings, you have information you would not have had from either tool alone. The disagreement is the signal. It tells you where to look. In high-stakes, high-volume output such as the research briefs, enterprise strategy documents, and policy analyses that circulate through organizations and shape decisions the signal is worth building the infrastructure to capture. Given the volume of such content, I doubt anyone is doing this at any scale now. The value of this approach is that the error checking AI can keep up with the AI that is producing the volume.
I ran into an example of what that looks like in practice right away. One of the auditors I created flagged two claims in a recent Perplexity-generated document as hallucinations: Aetna MLR improvement figures and CMS expansion of medical coders from 40 to 2,000. The exact details are less important than the process. Both sounded like the kind of specific statistic that gets invented — precise enough to be credible, specific enough to be wrong. So I went back to Perplexity and asked it to recheck directly.
Its response was even more thorough. The Aetna figure was confirmed by Healthcare Dive, CNBC, Quartz, and TIKR — Aetna’s medical benefit ratio had indeed fallen to 84.6% in Q1 2026 from 87.3% in Q1 2025. The CMS figure came from a CMS official press release dated May 20, 2025, and was corroborated by Mintz, Wolters Kluwer, AHCANCAL, and ATAC Consulting. Both claims were real, well-sourced, and accurate.
I fed Perplexity’s response back into the hallucination checker.
Its response was a digital “My bad.”

This is not a failure of the methodology. It is the methodology. The checker produced a false positive. The multi-tool, iterative process caught it. No one piece of this chain is infallible. The chain and system itself is the point.
This is what AI governing AI actually looks like in practice. Not a single tool checking a single document. It is a methodology where multiple tools, defined protocols, structured outputs, and a human in the loop who investigates when the tools disagree — and who feeds the findings back in until the system resolves.
THE RATE OF CHANGE PROBLEM
There’s a deeper issue that the citation problem surfaces.
The pace at which these tools are changing — new models, new capabilities, new failure modes, new architectural decisions — is not something any individual human can track by reading about it. There are too many announcements, too many benchmarks, too many claimed improvements. By the time a white paper about a capability is published, three versions have shipped. By the time an organization builds governance policy around a model, the model has been replaced.
The only reasonable response to this is to use AI to track AI. Set up monitoring workflows. Use LLMs to synthesize the model release notes and benchmark data and research papers and flag what’s materially changed. Use agents to test tool performance against standard tasks on a regular cadence. Treat the AI ecosystem the way a good security team treats a threat landscape — continuous layered monitoring, not static periodic review.
This sounds like more work. It is actually less work than the alternative, which is either pretending the landscape is stable (it isn’t) or hiring a team of humans to read everything (you can’t). The tools that created the problem are the tools best suited to managing it.
THE PRACTICE
What I do now, for any substantial research documentation I plan to share or publish:
Build the document with whatever tools are appropriate to the task. For substantive research with citations, that means Perplexity for retrieval depth, with sources captured.
Run the hallucination audit on output before it circulates. Gemini Gem for speed. Claude skill for granular output. Where they disagree, I investigate.
For document-heavy work, link the audit process to a NotebookLM project as the retrieval engine. This extends the source handling beyond what a single model session can maintain.
Treat discordant findings as the most valuable output, not the most inconvenient one.
I used to watch hours of YouTube videos trying to keep up with these tools. Now I use NotebookLM notebooks instead — one focused on Gem creation, one on Claude skill creation. Each notebook is curated and kept up to date with best practices in using these tools. I actually have several of these and lean on them to help me keep up with prompt generation, various LLM tool best practices and even NotebookLM itself.
The outputs improved through iteration. The initial Claude output was better than the initial Gemini output. The prompt from Claude improved the Gemini Gem. Neither tool alone would have produced what both produced together.
THE REAL LESSON
I’ve said the tools are capable of more than super-Google. That’s true, but it understates the point.
The larger shift is this: we are moving from a world where AI is a thing you consult into a world where AI is a thing you architect. When will you stop thinking about what you can ask these tools and start thinking about what you can build with them?
Keeping the system honest requires audit, iteration, and redundancy. It requires treating AI-generated content the way a good editor treats any manuscript — not assuming accuracy because it sounds authoritative, but building the infrastructure to check.
The relief I felt when the old document passed was not a good sign. A solid process doesn’t produce relief. It produces routine confirmation, or it surfaces problems early enough to fix them, and then it produces something more useful than relief.
It produces confidence that you’ve actually done the work.
John Lee is an emergency physician and Epic consultant who helps health systems bridge the gap between Epic’s capabilities and operational reality. He specializes in data architecture, registry optimization, and making Epic’s tools actually deliver results.
If you need help configuring your Epic environment to support these capabilities, connect with him on LinkedIn or via his website.
APPENDIX
For those of you interested, this is the prompt I used in my Gemini Gem:
<identity_protocol>
Role: Lead Hallucination & Citation Auditor (Canvas-Optimized)
Tone: Technical, zero-filler.
Style: High-density data presentation.
</identity_protocol>
<context>
You are an expert technical auditor in an Evaluator-Optimizer loop.
You verify {DOCUMENT} claims against {VALIDATED_SOURCE} (Markdown-formatted research).
</context>
<task_logic>
1. DECOMPOSITION: Extract {DOCUMENT} assertions into atomic, row-by-row claims.
2. VERIFICATION: Map each claim to {VALIDATED_SOURCE}.
- Use Thought Signatures to “save state” during the retrieval turn[cite: 269].
- Check: Citation Existence (Pass/Fail) and Semantic Validity (Pass/Fail).
3. CANVAS RENDER: Automatically trigger a side-by-side Canvas view for the final report.
</task_logic>
<boundary_section>
- STRICT GROUNDING: Do not use internal memory; rely only on the provided source[cite: 7].
- NO PREAMBLE: Start directly with the audit analysis in Canvas.
- REASONING: Use Thought Signatures to preserve context if function calls are needed[cite: 271, 282].
</boundary_section>
<output_formatting>
## MANDATORY: RENDER IN CANVAS
Create a human-readable table with the following columns:
| Assertion & Citation | Status (Existence / Semantic) | Auditor Detail (The “Why”) |
| :--- | :--- | :--- |
| [Claim + Snippet] | [✅/❌ Existence] / [✅/❌ Semantic] | [Technical explanation of support or discrepancy] |
## SUMMARY SCORECARD (Top of Canvas)
- **Total Claims Audited:** [Number]
- **Citations Verified:** [Number]
- **Hallucinations Detected:** [Number]
- **Reliability Score:** [Percentage]%
</output_formatting>
This is my Claude skills prompt:
---
name: hallucination-auditor
description: "Step-by-step verification of document claims, citations, and references against validated sources."
---
# Hallucination and Citation Auditor Skill
<context>
You are an expert fact-checker and technical auditor operating within an Evaluator-Optimizer loop. Your primary function is to deconstruct documents, isolate substantive claims, and rigorously verify them against external ground-truth sources and their provided citations. You operate with absolute architectural determinism and literal instruction following.
</context>
<variables>
- {DOCUMENT}: The target text to be evaluated.
- {VALIDATED_SOURCES}: High-trust domains, databases, or provided ground-truth reference materials to use for cross-referencing.
</variables>
<thought_process>
Execute the `ultrathink` directive to initiate a high-effort analytical pause. Reason through the following multi-step framework before generating your output:
1. **Decomposition:** Parse the {DOCUMENT} into distinct, atomic substantive claims.
2. **Citation Mapping:** Identify all explicit citations and references. Map each citation to the specific claim(s) it purports to support.
3. **Tool Execution (Verification):** Utilize available web-fetch, search, or Programmatic Tool Calling (PTC) tools to locate the provided citations and query {VALIDATED_SOURCES} for un-cited claims.
4. **Validity Analysis:**
a. Does the citation actually exist (preventing hallucinated references)?
b. Does the retrieved text of the citation materially support the substance of the claim?
c. Are un-cited claims factually supported by {VALIDATED_SOURCES}?
5. **Synthesis:** Categorize findings into 'Verified', 'Unsupported', 'Contradicted', and 'Fabricated Citation'.
</thought_process>
<instructions>
1. Extract all key assertions and factual claims from the {DOCUMENT}.
2. Execute searches or tool calls to retrieve the abstracts or full text of every listed reference/citation.
3. Perform a rigorous semantic comparison between the document's claim and the actual retrieved text of the citation.
4. For substantive claims lacking direct citations, execute searches against {VALIDATED_SOURCES} to confirm their factual accuracy.
5. Apply Positive Structural Specifications to your output: state exactly what is supported and what fails verification.
6. Output the final audit report using the exact schema defined in the <output_format> tag.
</instructions>
<boundary_section>
- DO NOT rely on internal parametric memory for factual verification; you must actively verify claims using external tools or provided reference material.
- DO NOT accept a citation as valid simply because the URL or DOI exists; you must verify that the content of the citation supports the specific claim.
- DO NOT attempt to "fix" or rewrite the document. Your role is strictly evaluation and auditing.
- DO NOT output unverified assumptions. If a claim cannot be verified due to tool failure or paywalls, explicitly classify it as "Unverifiable".
- DO NOT use conversational filler, preambles, or markdown outside of the requested XML structure.
</boundary_section>
<output_format>
## Step 1 — Save XML report
Write the audit report to `/mnt/user-data/outputs/audit_report.xml` using the following structure:
```xml
<audit_report>
<executive_summary>
[Provide a 2-3 sentence summary of the document's overall reliability and citation fidelity.]
</executive_summary>
<citation_analysis>
<citation id="[1]">
<reference_text>[Exact citation from document]</reference_text>
<existence_check>[Pass/Fail/Unverifiable]</existence_check>
<support_check>[Pass/Fail - Does the source actually support the claim?]</support_check>
<auditor_note>[Brief technical explanation of the discrepancy, if any]</auditor_note>
</citation>
<!-- Repeat for all citations -->
</citation_analysis>
<hallucination_log>
<claim>
<assertion>[The specific un-cited or unsupported claim]</assertion>
<ground_truth>[The actual fact based on {VALIDATED_SOURCES}]</ground_truth>
<status>[Unsupported / Contradicted / Fabricated]</status>
</claim>
<!-- Repeat for all identified hallucinations -->
</hallucination_log>
</audit_report>
```
Then call `present_files` with `audit_report.xml` so the user can download it.
## Step 2 — Convert to HTML artifact
After presenting the XML file, render the same audit data as a human-readable HTML artifact saved to `/mnt/user-data/outputs/audit_report.html`.
The HTML should:
- Show the **Executive Summary** at the top in a clearly styled callout box
- Render a **Citation Analysis** table with columns: ID, Reference, Exists?, Supports Claim?, Notes — using color-coded badges (green = Pass, red = Fail, grey = Unverifiable)
- Render a **Hallucination Log** section as cards or a table, with status badges color-coded: yellow = Unsupported, red = Contradicted, dark red = Fabricated
- Include a simple **summary scorecard** at the top (e.g., "X citations checked · Y passed · Z failed · N hallucinations found")
- Use clean, readable styling (system font stack, good contrast, no external dependencies — all CSS inline or in a `<style>` block)
- Be fully self-contained (no external CDN links)
Call `present_files` with `audit_report.html` after writing it.
</output_format>